Operations Research: A Supply Chain Perspective
In this final introduction to OR in the supply chain, we discuss facility location choices, and the common techniques that are used to geographically position plants and DCs, in order to provide demanded services. These methods are essential to the optimal design of network structures. They are widely applied, including to emergency facility placement as well as public and retailing services.
In any supply chain, the closer facilities are located to customers, the faster the delivery response time becomes (assuming the goods are ready to ship!). We can take weighted average distance as an indicator of service and transportation costs. Since the distribution process is the final link in the supply chain, decisions relating to infrastructure are likely to be strategic.
As these decisions can influence whether or not goods circulate efficiently in the distribution system, it is easy to see that network design is key to efficient supply chain operations. In fact, the placement of facilities and the optimal assignment of customers not only improves the flow of materials and services, but also utilises the plants in an efficient way. This can ultimately prevent the use of duplicated (or redundant) facilities.
One possible strategy is to open premises with a fixed capacity to serve a market. The capacity decision has an immediate effect on the distribution system, and the reduction in the number of sites facilitates economies of scale. Centralisation generally increases efficiency at the expense of responsiveness – since many customers are situated far from the plants. However, if the customer demands it and is willing to fund rapid response, the company may choose to install several premises. This is generally the case for online shopping, where companies can rapidly provide service to the customer network using many intermediate hubs. On the other hand, locating premises in close proximity to customers increases responsiveness at the cost of reducing efficiency.
There are a variety of models developed to solve location problems, and in supply chain operations, the simplest is the centre-of-gravity (CoG) method.
The Centre-of-Gravity Model
is generally used to locate a single facility and assumes that the distribution cost is a function of the quantity of the load, and the square of the straight-line distances. The distances in each of the location coordinates are averaged using the demand quantities as weights, and the resultant coordinates constitute the centre-of-gravity for that particular region. Despite its appeal and simplicity, this method can be flawed for formal network design solutions.
As distances are based on straight-line estimates, CoG cannot exploit information regarding existing road networks. It could also potentially lead to undesirable locations, for example, in a sea, on a mountain, and so on. Regardless, CoG is useful in providing intuition or a basic approximation at the start of any network model construction.
In what follows, we discuss the so-called Facility Location Problem (FLP). FLP is a classic optimisation method that is used to determine the best geographical location for a plant or warehouse, based on demand, transportation distances and facility costs.
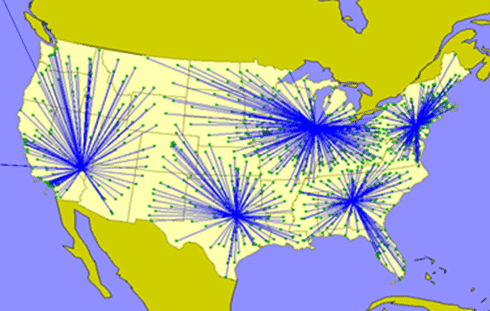
The Facility Location Problem
is concerned with selecting the best among potential sites, subject to constraints requiring that demands at particular points are serviced by the established facilities. The objective is to select those sites that minimise costs. These typically include a cost that is proportional to the sum of the distances from the demand points to the servicing facilities (in addition to activation costs associated with opening selected sites, running costs, etc.). The facilities may or may not have limited capacities for servicing, which respectively classifies the problems into capacitated and uncapacitated variants.
In general, FLP models are designed to address the number of facilities required, the location of each site and the capacity that is required to serve at each location. In all cases, each model must be constrained where the type of restrictions depends on the nature of the problem.
Common constraints include:
- Each site may have a specified capacity limitation
- Customers / Retailers may decide to receive their goods from a particular facility
- Retailers may operate to a set delivery day schedule and time window
Formally, location problems are classified as combinatorial (i.e. they involve searching for an optimal object from a finite set of objects). There are generally two types of algorithms used to solve them, namely: exact and heuristic procedures. The former guarantees an optimal solution is returned. This introduces a serious bottleneck in the computation process, since the time required to arrive at the solution is usually enormous (i.e. computationally expensive).
However, its less expensive and faster counterpart is the heuristic, an approximation algorithm. It starts with a predetermined set of solutions while trying to identify a near-optimal solution. Basically, this rule-of-thumb process guides the algorithm towards a feasible region. These rules often provide some modifications to the incumbent solution, as well as procedures to further explore the solution space of the problem.
Therefore, in supply chain network design, exact algorithms are best-suited only for small-scale problems, where models are usually formulated using integer linear programming, in which at least one decision variable is integer-valued. These variables are typically binary-valued to identify whether a facility is active or inactive by being assigned a value of 1 or 0, respectively.
On the other hand, solving larger (more realistic) problems with large data sets remains difficult, and heuristic procedures, such as simulated annealing and genetic algorithms are needed. Fortunately, recent advances in high-performance computing provide high-quality solutions within a short time.
The p-Median
is a powerful technique that finds the optimal spatial arrangement of multiple sites – exactly p facilities, so that weighted average distance from customers to their closest warehouse is minimal. The principle is simple; regions having nodes of large demand will tend to attract warehouse facilities closer. If we can improve the average distance, it is likely that we will have more customers closer to warehouses.
To construct this model, we require information on the geographic location and demand for each customer. Also needed is a list of potential (i.e., candidate) warehouses whose location and capacity are also known in addition to the constraints. One typical constraint may be, for example, any inactive warehouse cannot be assigned to serve a customer.
When the model is then run across multiple scenarios, the weighted average distance is evaluated for each case. This provides guidance on the marginal value of introducing further warehouses to a network. Interestingly, it is found that benefits diminish with each incremental location (see Fig 1).
Furthermore, weighted average distance can be taken as a good approximation to service. We can then examine the demand serviced within a specified range of a candidate site, and this can provide valuable insights on delivery response and distribution lead times.
In running multiple model options, this technique supplements our strategic understanding of the supply chain network. It helps us understand the trade-offs and business implications of switching on (and off) sites.

{kind=link}
Fig. 1 Diminishing returns effect
Summary
In this brief series, we introduced some key applications of OR in the supply chain. We hope this has provided an insight into the relevance of this interdisciplinary subject.
Many models developed in OR continue to be motivated by real-life supply chain applications, but as we know – reality can be complex. In most cases, this increases the difficulty of building models that faithfully represent the behaviour of a supply chain system. Naturally, the more adjusted to reality a mathematical model is, the more complex it becomes. We can take a sensible approach by individually resolving each component in simplified versions of the real problem. Then, we can simply integrate multiple activities into a single problem that collectively contains and optimises the values of all decision variables.
As most of you will have noticed, in today’s supply chain, the words efficiency, optimisation and sustainability are repeatedly used. We can think of efficiency as the use of all available means to reach a goal. When this is (supposedly) reached with the minimum of resources, it then implies optimisation. However, complications now arise when decisions are being made to achieve this optimal result while now accounting for the sustainability of the proposed solutions.
Since challenges in the supply chain become challenges in OR, our goal is to construct models that connect these three key requirements. This is likely to involve more complicated structures that contain a greater number of decision variables and more constraints.
Finally, supply chain needs OR and, in turn, the needs that arise in the supply chain continue to drive new problems that OR will help to resolve.
Supply Chain Enabled